NATS 101
An introduction to NATS core from a beginners POV
Distributed systems can get nitty gritty and it can be overwhelming to handle them. Event brokers are often introduced to manage this complexity. Systems like Kafka, RabbitMQ, and NATS help services communicate without being tightly coupled, but they are built with different assumptions and tradeoffs. In this blog, we will focus on NATS Core. We will understand what NATS is designed to do, how it works at a fundamental level, and in which scenarios it is a better fit than other brokers.
Foundation
As systems grow, the number of moving parts grows with them. Services start producing more data, reacting to more events and depending on more components. And one request might trigger multiple downstream calls that makes the latency compounds. One slow service might start affecting others. At this point, teams usually look for a better way to let services communicate without being tightly coupled to each other. This is where event driven thinking starts to make sense.
What is an Event Broker ?
An event broker is a piece of infrastructure that sits between your services. It accepts events from producers and routes them to the relevant consumers. It severs the dependency between the sender and the receiver. Services interact with the broker instead of each other. If a service fails, the remaining system continues to operate as long as the connection to the broker holds. This isolation reduces downtime and prevents cascading failures.
In an event-driven system, services take on roles like:
A Producer that emits events. It remains unaware of the downstream environment. It publishes to the broker and returns to its execution context
A Consumer that subscribes to subjects of interest. It processes events without knowing the services that triggered them.
This separation allows both sides to evolve independently. Producers can add new events. Consumers can join or leave the system without requiring configuration changes to the producer. The broker acts as the stable interface which makes the system extensible.
Beyond decoupling, an event broker changes how systems experience load. In synchronous designs, spikes often propagate as cascading failures. With event-driven communication, producers are less tightly bound to consumer speed, which reduces immediate pressure on downstream services. Rather than crashing outright, the system tends to surface stress as processing lag. While not all brokers persist messages by default, this lag is still a useful operational signal and often the first indicator that flow control is needed.
About NATS Core
NATS Core is a lightweight event broker designed for fast, decoupled communication between services with minimal friction. It can be adopted incrementally without heavy operational overhead. At its core, NATS acts as a central relay. Producers publish messages to subjects. Consumers subscribe to the subjects they care about. It handles discovery using subjects rather than hostnames or ports that removes the need for services to know where other services live.
This subject-based model naturally supports many-to-many communication. One producer can publish an event that multiple consumers receive, and multiple producers can publish to the same subject without coordinating with each other.
NATS Core operates on an At-Most-Once quality of service. It is a fire-and-forget system that holds messages in memory so messages are not stored for later delivery. If no consumer with a matching subscription is listening at the moment a message is published, the message is dropped. It is a design choice to prioritize speed for ephemeral data flow.
For systems that need stronger delivery guarantees, NATS can be extended with Jetstream. Jetstream adds persistence and introduces At-least-once and exactly-once delivery semantics. This allows NATS to cover use cases where message durability and replay are required, which we will touch on later.
How it works
The messages are routed based on the subjects. Subjects are strings of alphanumeric characters separated by dots,
creating a logical hierarchy. So we can encode business semantics directly into the address of the message. A good practice is to use the first tokens to establish a general namespace and the final tokens for specific identifiers: orders.eu.north.warehouse-101.created
Publishers always send messages to a fully specified subject. Although subscribers can use wildcards to observe multiple data streams with a single connection. The single token wildcard ( * ) matches exactly one element at a specific level of the hierarchy. So, the subject orders.eu.*.warehouse-101.created listens to order creation events across all European regions for that specific warehouse. The full wildcard ( > ) matches all tokens from its position to the end of the subject. In this case, orders.eu.> captures every event within the entire European order namespace
This hierarchy transforms the subject into a structured map of our application data flow. By defining our subjects carefully, we can create a system that is easy to scale.
Messaging capabilities
Request-Reply
While publish–subscribe is ideal for event distribution, many distributed systems also require direct interaction patterns like Request–Reply. NATS implements Request–Reply using the same publish–subscribe mechanism. A request is published on a subject along with a reply subject, called an inbox. This inbox is a unique, dynamically generated subject tied to the requester.
Responders subscribe to the request subject. When they process a request, they publish the response to the provided inbox where NATS makes sure that the response is routed back to the original requester.
 When multiple instances of a service listen to the same request subject, NATS allows for different interaction models. In a high concurrency environments, a requester might adopt an optimistic approach by accepting the first response that arrives and ignoring subsequent ones, which reduces tail latency in distributed searches.
Also, the system can handle aggregated responses where the requester waits for a specific count or until a timeout occurs to gather data from multiple sources. For standard processing, there are queue groups to distribute the request to a single member such that
only one instance handles the task that prevents redundant computation across the cluster.
When multiple instances of a service listen to the same request subject, NATS allows for different interaction models. In a high concurrency environments, a requester might adopt an optimistic approach by accepting the first response that arrives and ignoring subsequent ones, which reduces tail latency in distributed searches.
Also, the system can handle aggregated responses where the requester waits for a specific count or until a timeout occurs to gather data from multiple sources. For standard processing, there are queue groups to distribute the request to a single member such that
only one instance handles the task that prevents redundant computation across the cluster.
Queue groups
We have looked at the default delivery model in NATS Core which is 1:N fan-out. When multiple subscribers listen on the same subject, every published message is delivered to all of them. This is ideal for event distribution where multiple systems need to react independently to the same event.
Service workloads are different. When we scale a service horizontally, we want multiple instances running, but every instance need not process the same request. We want parallelism without duplication. Queue groups address exactly this problem.
A queue group is formed when multiple subscribers register on the same subject using a shared queue name. From that point forward, those subscribers act as a single logical consumer group. When a message is published on that subject, NATS delivers it to only one member of the queue group. The selection is handled by the server, and no coordination between service instances is needed.
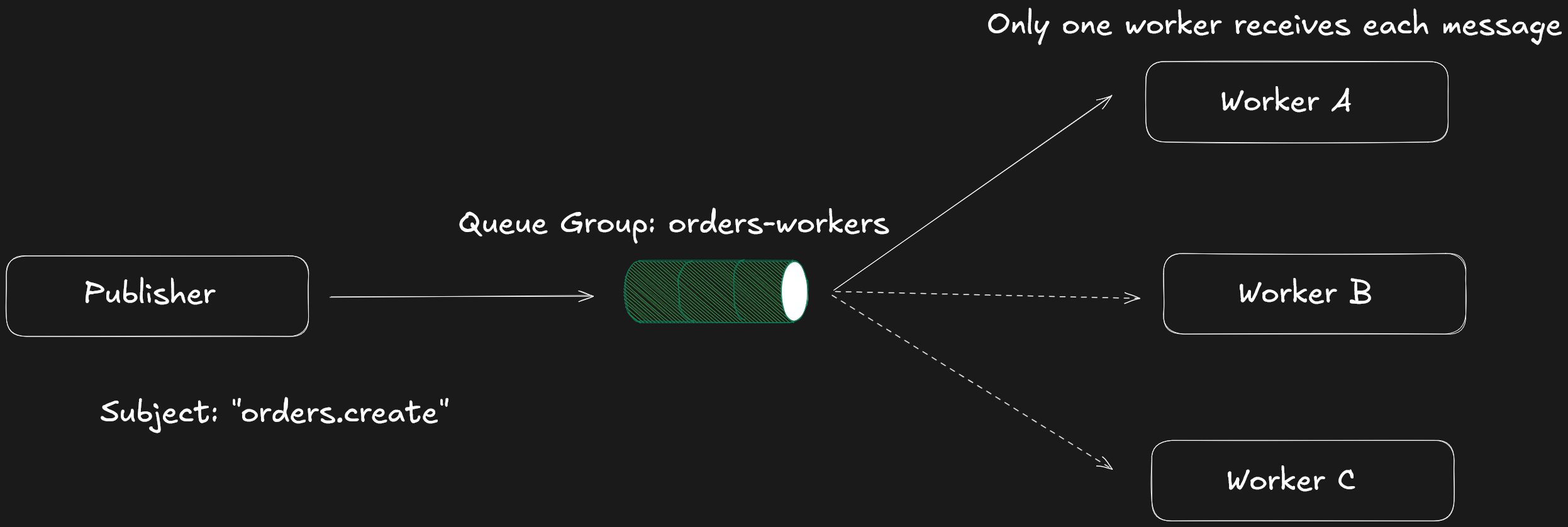
This transforms delivery model from broadcast to competing consumers. Each message is processed once per queue group. Adding capacity becomes a matter of starting another instance of the service with the same queue name. Removing capacity is equally straightforward: drain the connection and terminate the process. There Membership is defined entirely by the applications.
Queue groups provide built-in load distribution at the messaging layer. They eliminate the need for an external coordination mechanism for many service communication patterns. For request–reply workflows, they allow multiple service instances to handle traffic while preserving the simplicity of subject-based routing.
Concurrent Message Processing
Now, when a subscription is created in NATS Core, messages delivered to that subscription are processed sequentially. The client receives a message, handles it, and then moves on to the next one. This model is simple and predictable, it avoids accidental race conditions in application code. Queue groups extend this model horizontally by distributing messages across multiple service instances. However, scaling across processes is only one dimension of throughput. In many cases, it is also desirable to process multiple messages concurrently within a single service instance.
Most NATS client libraries support this pattern. Instead of handling each message synchronously, a subscriber can dispatch work to a worker pool. This allows a single service instance to process multiple messages in parallel while still receiving them over a single subscription.
Concurrency, combined with queue groups, provides two complementary scaling axes. Queue groups distribute load across service instances while concurrent processing increases throughput within each instance. They allow systems to scale efficiently without adding complexity at the messaging layer.
Why NATS is so fast
Protocol parser
NATS achieves high performance through a combination of a lean protocol design and a highly optimized server implementation. Unlike legacy brokers that rely on binary formats, NATS uses a text based wire protocol. This publish-subscribe model communication layer runs over standard TCP/IP sockets and issue a small set of operations (CONNECT, PUB, SUB, etc). The protocol allows for easy implementation across many programming languages without sacrificing performance. While text-based protocols are often perceived as slower than binary alternatives, NATS overcomes this through an efficient parsing strategy. The heart of the server is a zero allocation byte parser.
A zero allocation parser processes incoming data by reusing existing memory buffers instead of requesting new memory from the system for every message. This approach prevents the garbage collection overhead that typically slows down managed languages. The NATS parser handles split buffers and text-to-integer conversions with a near zero memory footprint. The NATS server is rewritten in Go which provides optimized base data structures and a sophisticated scheduler that manages thousands of concurrent client connections.
Subject Routing
In a system supporting multiple patterns like pub/sub, queue groups; message routing is a critical performance bottleneck. NATS solves this by using a modified Patricia trie, which is a variant of the Radix trie, as the backing store for its subject distributor.
A radix trie is a compressed trie optimized for prefix matching. Instead of storing each token separately, shared prefixes are collapsed, allowing related subjects like orders.eu.north.warehouse and orders.eu.west.retail to share structure internally. This makes hierarchical subject matching extremely efficient. When a message is published, the distributor walks the radix tree, collecting both standard subscribers and queue group subscribers in separate result sets. The routing path is deterministic and lightweight
The performance of NATS relies on more than just the tree structure. Because many concurrent goroutines access this distributor, a shared L2 cache sits in front of the Patricia trie to handle frequent lookups under traditional locking schemes. To further scale, each ingress processor maintains its own independent, lock-free L1 cache. This approach minimizes lock contention often becomes the limiting factor in high concurrency systems. Instead of relying on complex lock-free algorithms or Compare-And-Swap Operations that can be difficult to maintain, it uses a generational ID check. If a change occurs in the subject distributor, the L1 caches are invalidated and repopulated. This pragmatic engineering allows a single NATS server to process millions of messages per second making sure that the routing logic never throttles the network.
So far, everything we have discussed operates under at-most-once delivery. Messages are routed efficiently, distributed across workers and processed concurrently but they are not being persisted by default. What happens if a consumer is offline? How do we replay events or guarantee delivery? These questions lead us to Jetstream, NATS persistence and streaming layer, which we will talk about in the next part. After understanding both NATS Core & Jetstream in isolation, we will then see how NATS fits relative to other messaging systems such as Apache kafka and RabbitMQ.
This concludes the first part of our introduction to NATS Core. I hope that you learnt something new today.